SlowFormer: Adversarial Attack on Compute and Energy Consumption of Efficient Vision Transformers
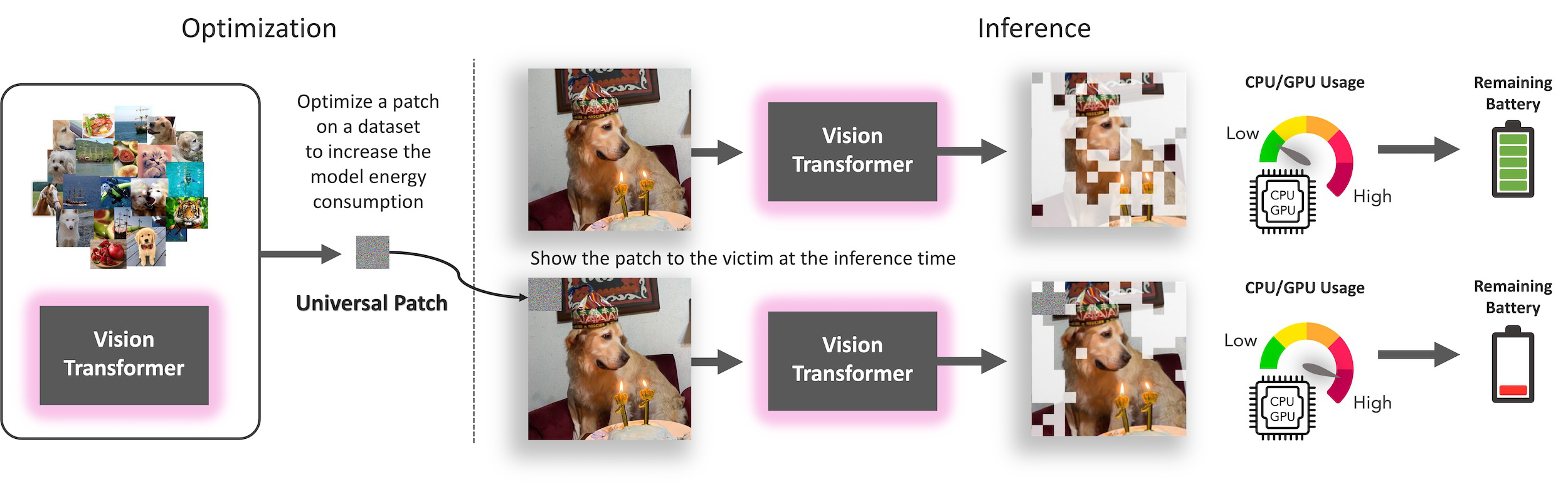
SlowFormer is an adversarial attack that affects the efficiency of adaptive inference methods for image classification. Input adaptive methods can reduce the computation at test time by avoiding the processing of unnecessary regions (e.g. token dropping) or by modifying the architecture (e.g. early exit, layer skip). We propose a universal adversarial patch attack that aims to increase the computation of such inputs to the maximum possible level. We show that such efficient methods are vulnerable to compute adversarial attacks and propose a defense mechanism.
Navaneet K L*, Koohpayegani, S.A.*, Sleiman, E.*, Pirsiavash, H., (2024). "SlowFormer: Adversarial Attack on Compute and Energy Consumption of Efficient Vision Transformers." IEEE Conference on Computer Vision and Pattern Recognition (CVPR).