Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
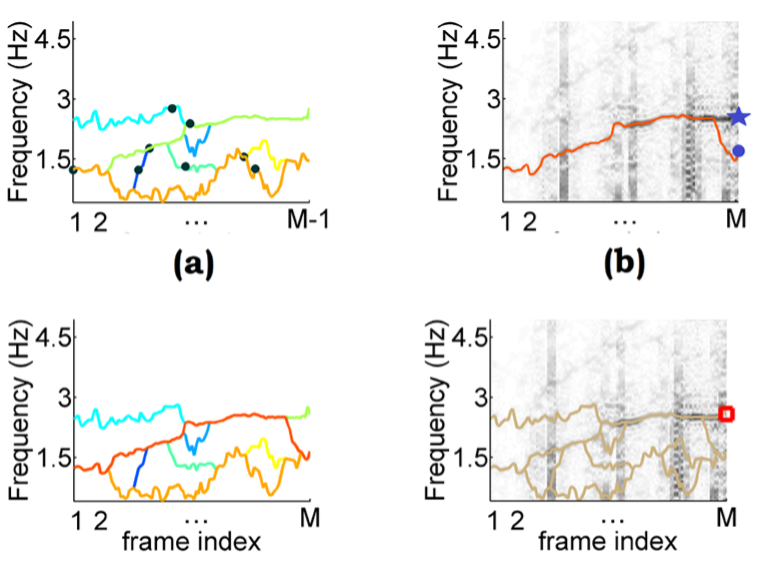
This paper is on effectively predicting heart rates from PPG signals in the presence of significant motion artefacts. We show that using multiple initialization points in spectral peak tracking provides a robust estimate of the heart rate.
Navaneet K L, Madhusudana P.C, Suresha P, Periyasamy V, Ghosh P.K. (2015). " Multiple Spectral Peak Tracking for Heart Rate Monitoring from Photoplethysmography Signal during Intensive Physical Exercise." IEEE Signal Processing Letters.
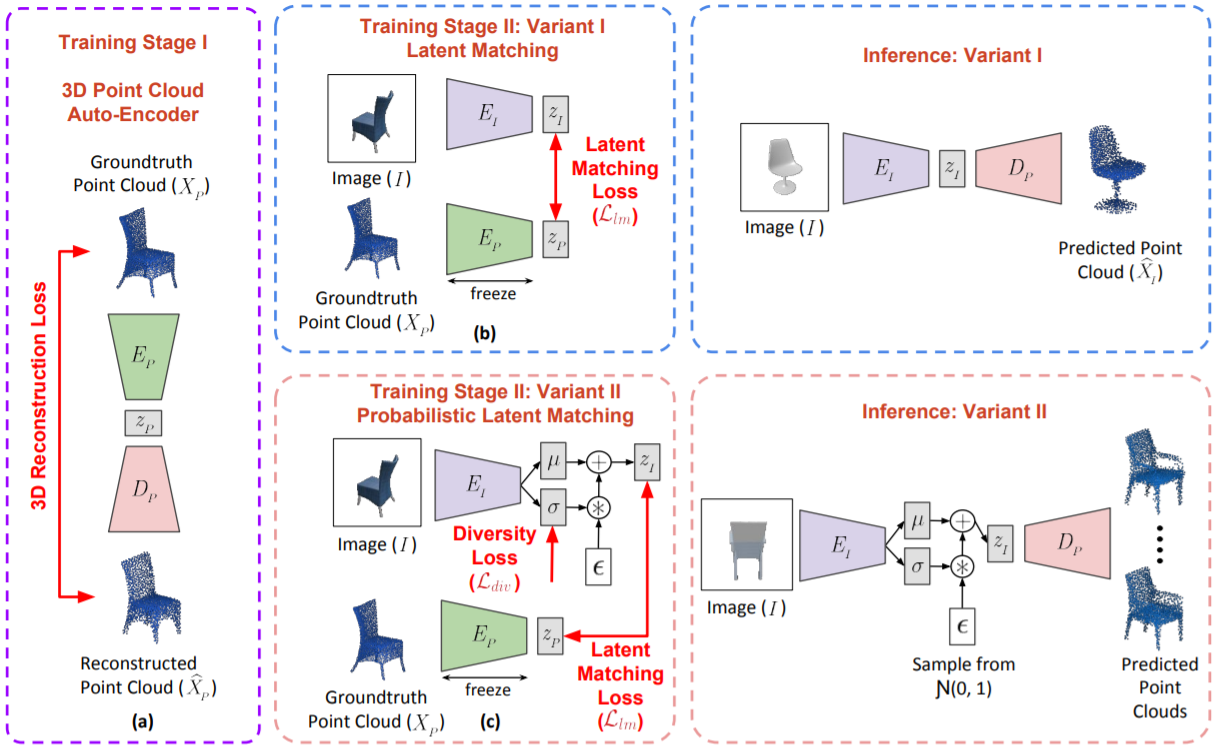
In 3D-LMNet, we match the latent embeddings of 2D and 3D encoder networks to facilitate effective 3D reconstruction from 2D image. We also explore generating multiple plausible reconstructions from ambigous images.
Mandikal, P.*, Navaneet K L*, Agarwal, M.* and Babu, R.V. (2018). "3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image." British Machine Vision Conference (BMVC).
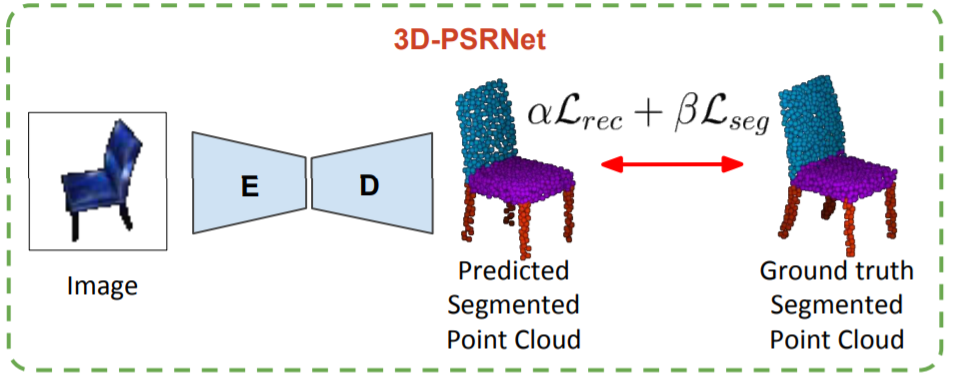
In 3D-PSRNet, we simultaneously perform 3D reconstruction and semantic segmentation to improve performance on both the tasks.
Mandikal, P.*, Navaneet K L* and Babu, R.V.(2018). "Part Segmented 3D Point Cloud Reconstruction from a Single Image." 3DRMS, ECCV Workshops.
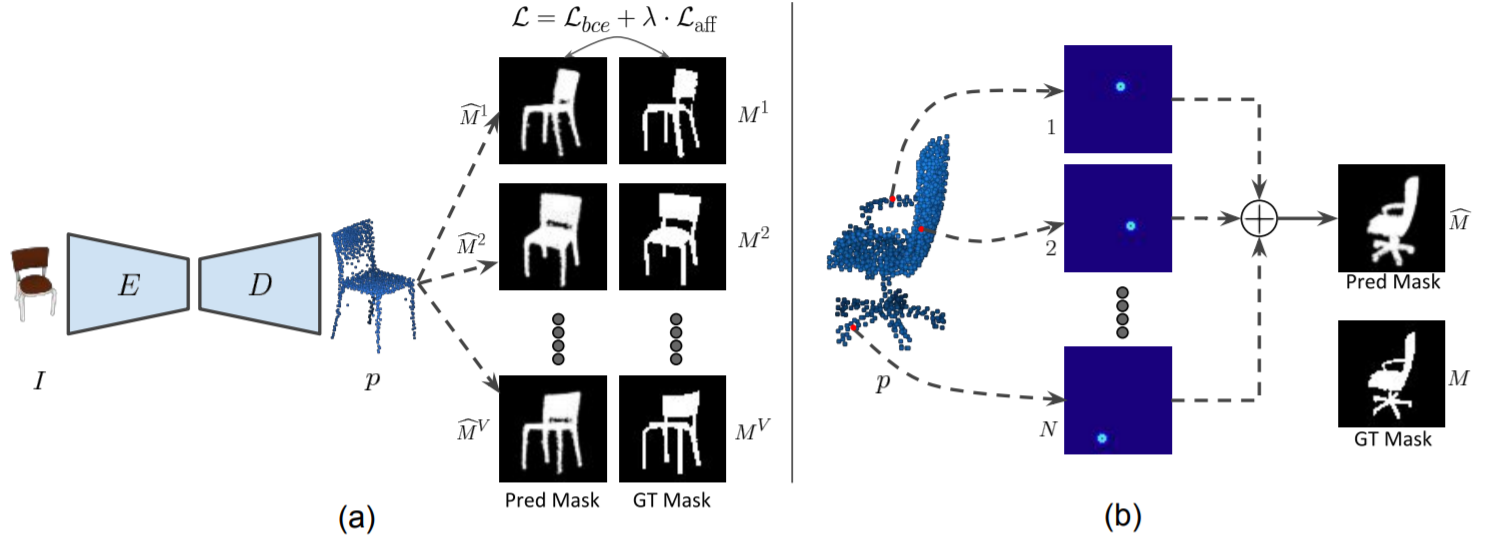
CAPNet uses differentiable rendering to project 3D point clouds onto 2D. This enables training 3D reconstruction network using 2D supervisory data.
Navaneet K L*, Mandikal, P.*, Agarwal, M and Babu, R.V. (2019). "CAPNet: Continuous Approximation Projection for 3D Point Cloud Reconstruction Using 2D Supervision." AAAI.
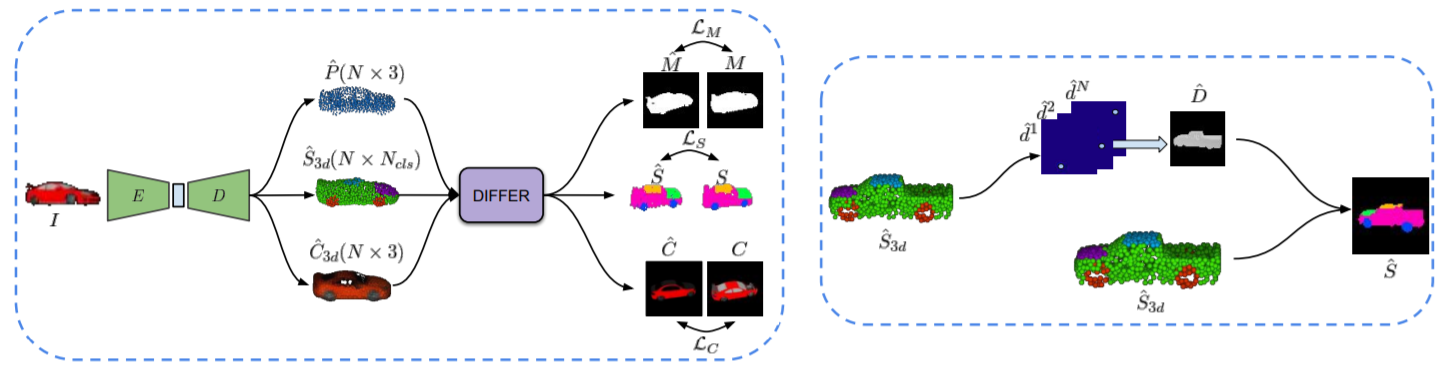
DIFFER extends CAPNet to reconstruct colored 3D point clouds from single RGB image. The differentiable renderer is modified to project features associated with a point onto 2D image.
Navaneet K L, Mandikal, P., Jampani, V. and Babu, R.V. (2019)." DIFFER: Moving Beyond 3D Reconstruction with Differentiable Feature Rendering. " 3DWiDGET, CVPR Workshops.
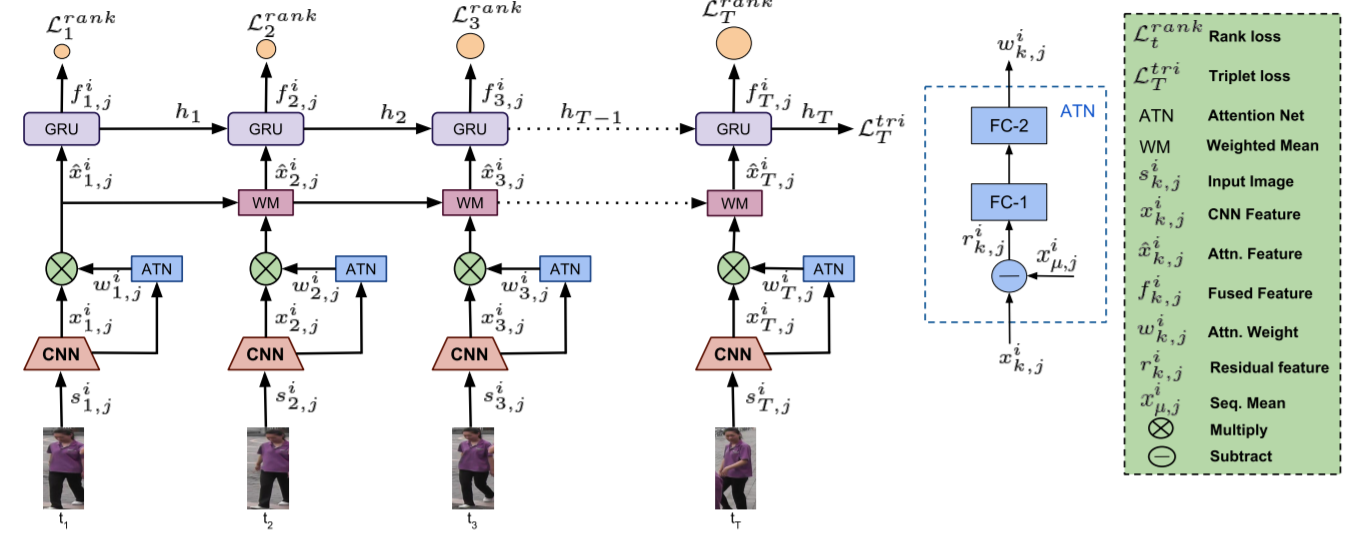
This work proposes a novel loss function for improving video based person re-identification as more frames are aggregated.
Navaneet K L, Todi V., Babu, R.V. and Chakraborty, A. (2019). "All for One: Frame-wise Rank Loss for Improving Video-based Person Re-identification." ICASSP.
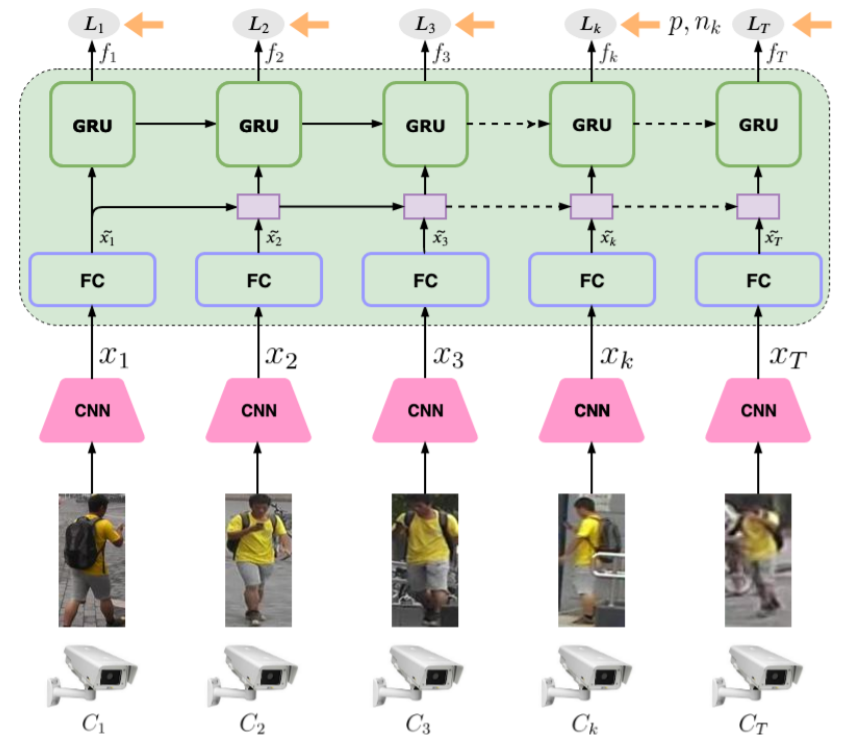
We propose a novel framework for multi-camera person re-identification. We introduce a human-in-the-loop methodology to sustain or improve re-id performance as images from more cameras are integrated.
Navaneet K L, Sarvadevabhatla, R.K., Shekhar, S., Babu, R.V. and Chakraborty, A. (2019). "Operator-In-The-Loop Deep Sequential Multi-camera Feature Fusion for Person Re-identification." IEEE Transactions on Information Forensics and Security.
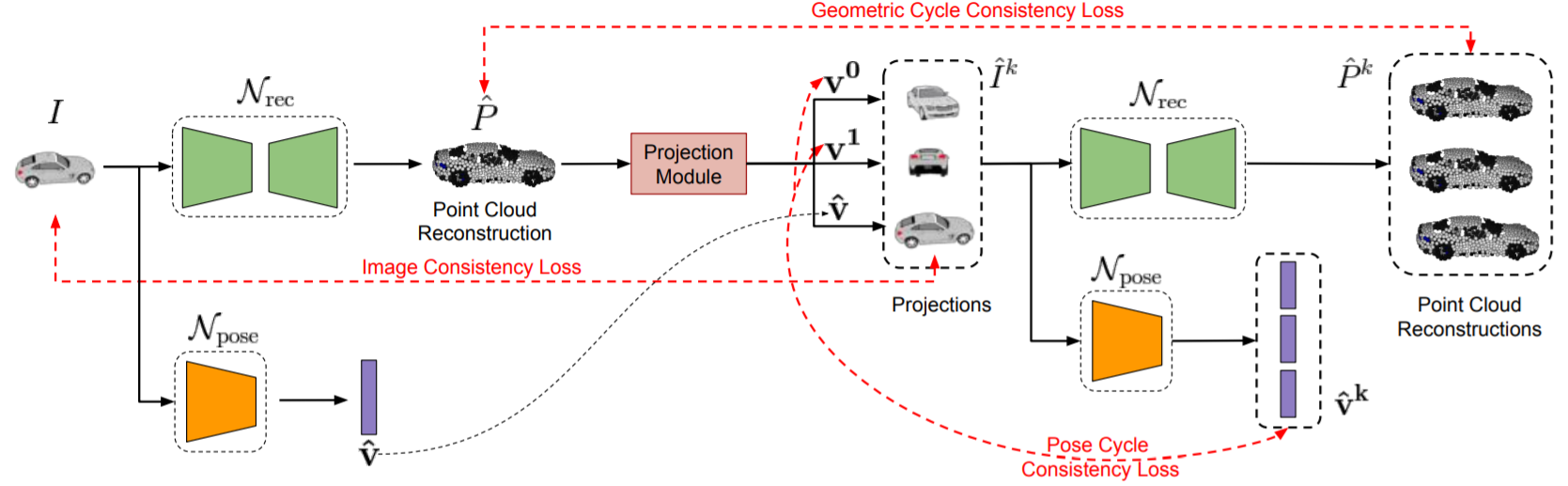
We aim to reconstruction 3D point clouds from single image inputs in a self-supervised manner. The input RGB image and corresponding foreground mask are used as supervisory signals in the absence of supervised 3D, multi-view 2D or pose information.
Navaneet K L, Mathew, A., Kashyap, S., Hung, W., Jampani, V., Babu, R.V., (2020). "From Image Collections to Point Clouds with Self-supervised Shape and Pose Networks." IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
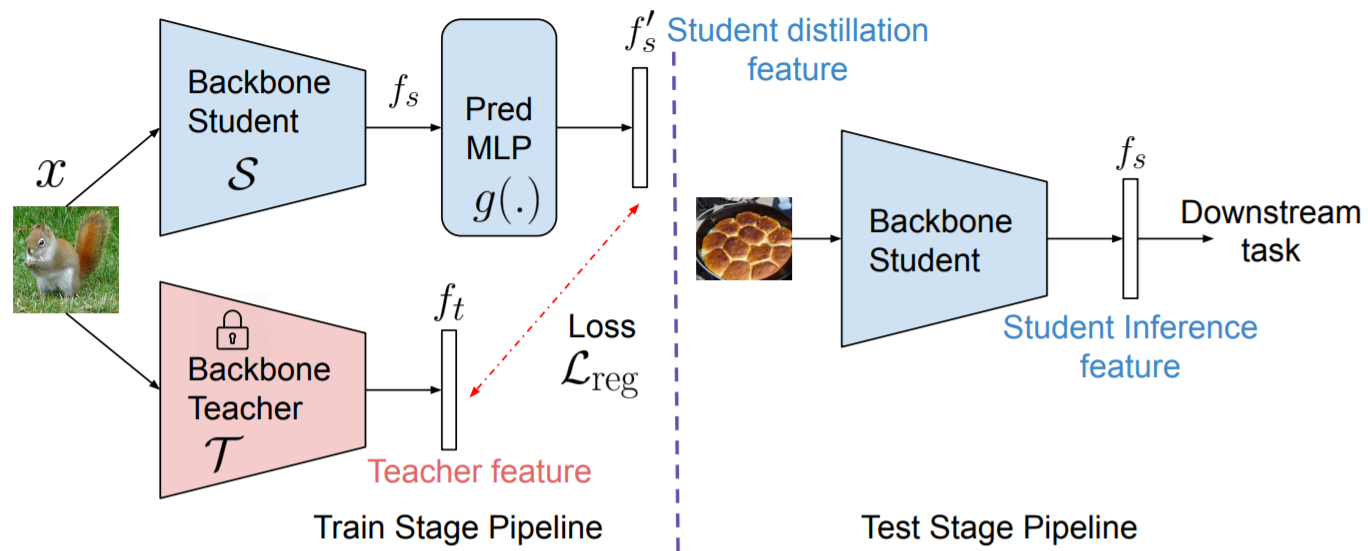
In SimReg, we show that simple regression works as well as more complex state-of-the-art methods on self-supervised knowledge distillation. We find that using an additional MLP-head atop the CNN base architecture, even if only during the train stage, results in superior performance on downstream tasks.
Navaneet K L, Koohpayegani, S.A., Tejankar, A., Pirsiavash, H., (2021). "Regression as a Simple Yet Effective Tool for Self-supervised Knowledge Distillation." British Machine Vision Conference (BMVC).
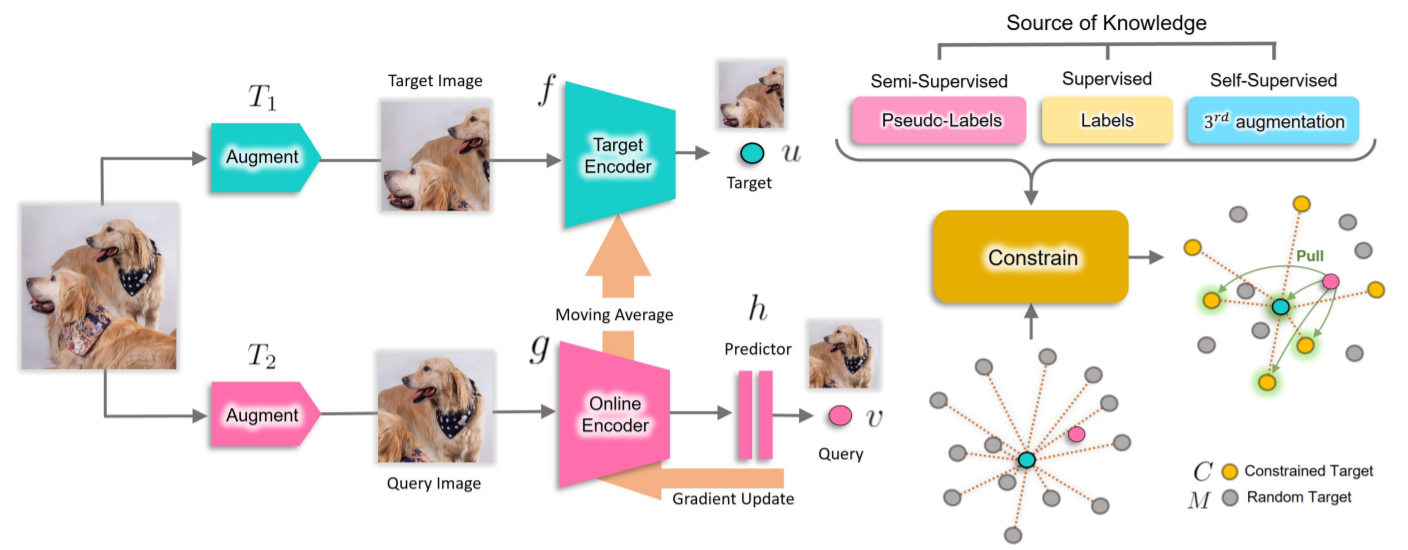
CMSF extends a prior self-supervised representation learning method(MSF) where a sample is encouraged to be close to not just its augmented version but also to the nearest neighbors of the augmented image. In CMSF, the neighbors are constrained to be from the same semantic category as the input image. Use of constraint provides samples that are far from the target image in the feature space but close in the semantic space. The category labels are present in the supervised set-up and are predicted in the semi- and self-supervised set-ups.
Navaneet K L*, Koohpayegani, S.A.*, Tejankar, A.*, Pourahmadi, K., Subramanya, A., Pirsiavash, H., (2022). "Constrained Mean Shift Using Distant Yet Related Neighbors for Representation Learning." European Conference on Computer Vision (ECCV).
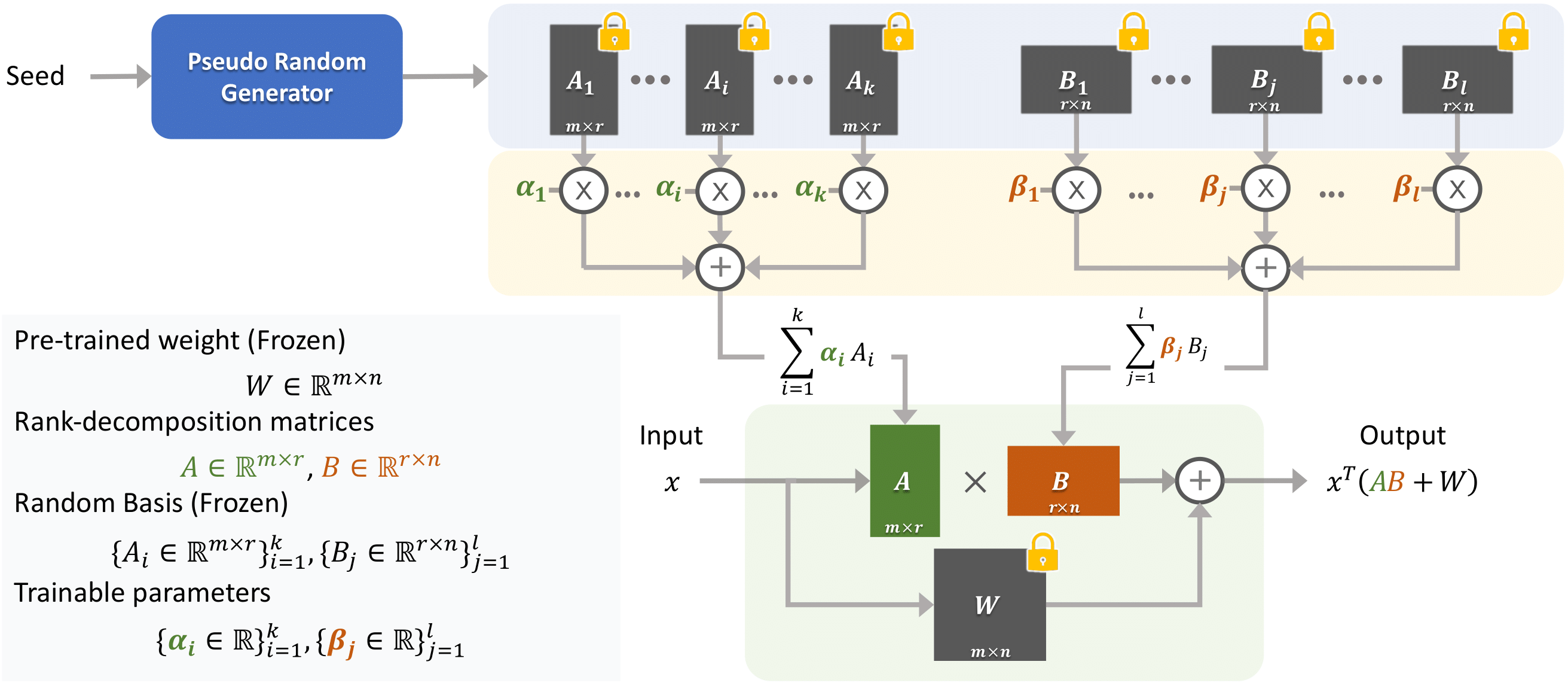
NOLA is a novel method for parameter-efficient fine-tuning of LLMs and vision models. In NOLA, we re-parameterize the low-rank matrices of LoRA using linear combinations of randomly generated matrices (basis) and optimizing the linear mixture coefficients only. This approach allows us to decouple the number of trainable parameters from both the choice of rank and the network architecture and helps overcome the rank one lower bound for number of parameters present in LoRA. We present adaptation results using GPT-2 and ViT in natural language and computer vision tasks. NOLA performs as well as, or better than models with equivalent parameter counts. We can halve the parameters in larger models compared to LoRA with rank one, without sacrificing performance.
Koohpayegani, S.A.*, Navaneet K L*, Nooralinejad, P., Kolouri, S., Pirsiavash, H., (2024). "NOLA: Compressing LoRA using Linear Combination of Random Basis." International Conference on Learning Representations (ICLR).
GeNIe is a data augmentation technique for image classification. It leverages a diffusion model conditioned on a text prompt to merge contrasting data points (an image from the source category and a text prompt from the tar- get category) to generate challenging samples for the tar- get category. Inspired by recent image editing methods, we limit the number of diffusion iterations and the amount of noise. This ensures that the generated image retains low- level and contextual features from the source image, po- tentially conflicting with the target category.
Koohpayegani, S.A., Singh, A., Navaneet K L, Jamali-Rad, H., Pirsiavash, H., (2023). "GeNIe: Generative Hard Negative Images Through Diffusion".
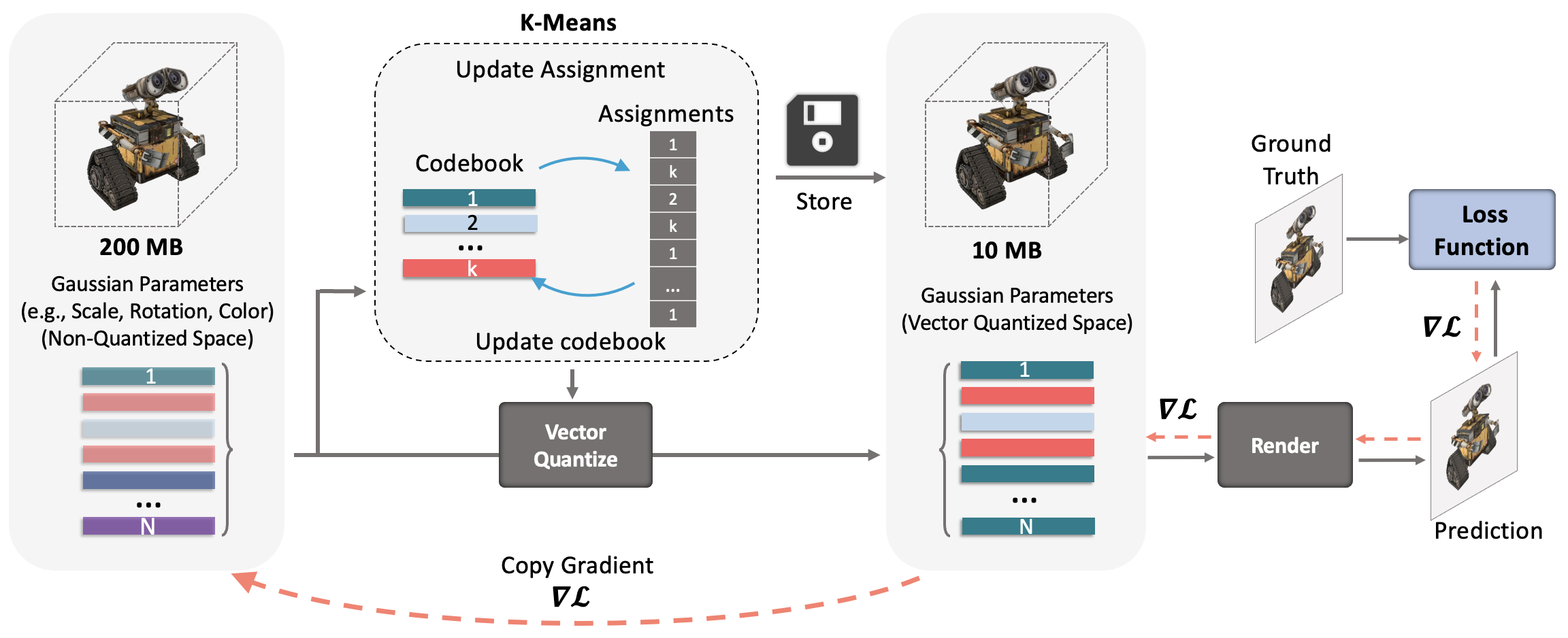
Compact3D is a method to compress 3D Gaussian Splat models. We notice that many Gaussians in 3DGS share similar parameters, so we introduce a simple vector quantization method based on K-means algorithm to quantize them. Then, we store the small codebook along with the index of the code for each Gaussian. Moreover, we compress the indices further by sorting them and using a method similar to run-length encoding.
Navaneet K L*, Meibodi, K.P.*, Koohpayegani, S.A., Pirsiavash, H., (2023). "Compact3D: Compressing Gaussian Splat Radiance Field Models with Vector Quantization".
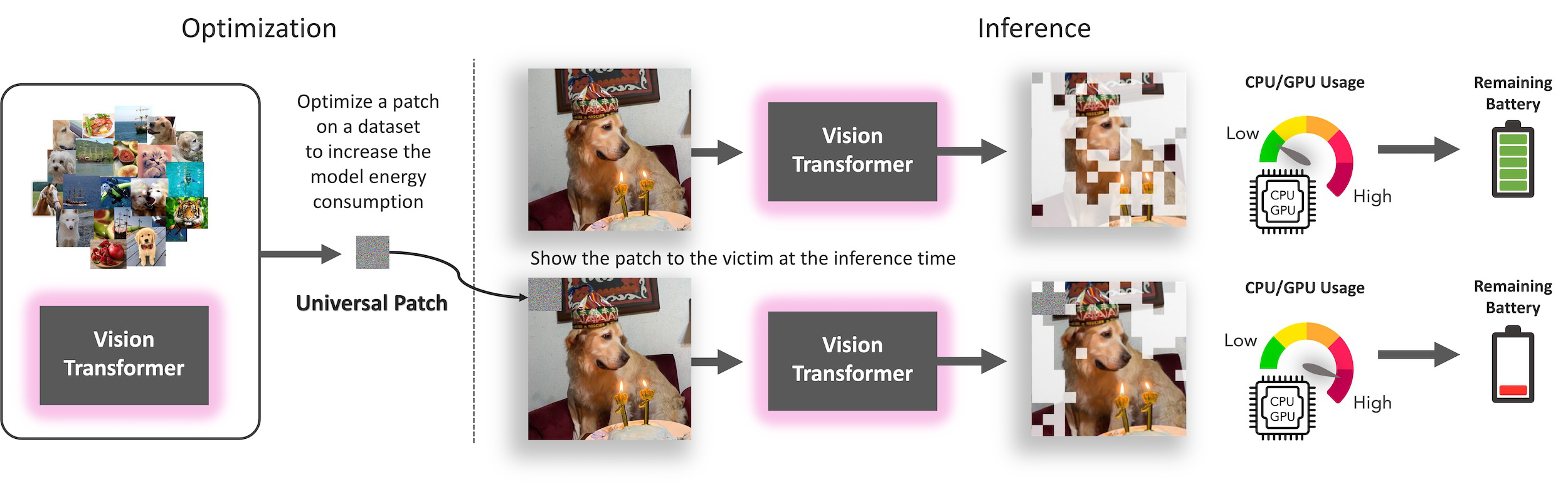
SlowFormer is an adversarial attack that affects the efficiency of adaptive inference methods for image classification. Input adaptive methods can reduce the computation at test time by avoiding the processing of unnecessary regions (e.g. token dropping) or by modifying the architecture (e.g. early exit, layer skip). We propose a universal adversarial patch attack that aims to increase the computation of such inputs to the maximum possible level. We show that such efficient methods are vulnerable to compute adversarial attacks and propose a defense mechanism.
Navaneet K L*, Koohpayegani, S.A.*, Sleiman, E.*, Pirsiavash, H., (2024). "SlowFormer: Adversarial Attack on Compute and Energy Consumption of Efficient Vision Transformers." IEEE Conference on Computer Vision and Pattern Recognition (CVPR).